Sim-To-Real: From Imitation to Reinforcement and Beyond
Abstract
This report details a comprehensive study on improving robot grasping capabilities, progressing from simple imitation learning to sophisticated reinforcement learning techniques and visual-based policies. Our experiments span various learning paradigms, input modalities, and model architectures, offering insights into the strengths and limitations of each approach.
1. Introduction
Robot grasping remains a fundamental challenge in robotics, requiring precise perception, planning, and control. This study aims to systematically explore and compare different learning approaches to solve this task, with a focus on sample efficiency, generalization, and real-world applicability.
2. Methodology
Our research progressed through several key stages, each building upon the insights from the previous:
2.1 Behavior Cloning with Diffusion Policies
We began with a pure imitation learning approach, leveraging recent advances in diffusion models for behavior prediction.
(1) Experimental Setup:
- Input Modalities: RGB images, later expanded to RGB-D
- Model Architecture: Transformer-based diffusion policy
- Dataset: 100 demonstrations (both simulated and real-world)
- Visual Encoders: ResNet18, CLIP (both global and local features)
(2) Key Explorations:
- Comparison of different visual encoders
- Impact of depth information on grasping performance
- Various action representations:
- Sample position
- Epsilon position
- Sample delta
- Epsilon delta
(3) Results:
- Achieved moderate success in simulated environments
- Real-world performance was limited, highlighting the reality gap
2.2 PPO with Demonstration Augmented Policy Gradient (DAPG)
Building on the limitations of pure imitation, we explored combining reinforcement learning with demonstrations.
(1) Experimental Setup:
- Input: State-based (robot joint positions, object poses)
- Model: Multi-layer perceptron (MLP) policy network
- Algorithm: PPO + DAPG
(2) Key Explorations:
- Reward structures:
- Dense reward (shaped for task completion)
- Sparse reward (binary success signal)
- BC weight (balancing RL and imitation objectives)
- Demonstration sources:
- 10 human demonstrations
- 100 human demonstrations
- 600 RL-generated demonstrations
- 3000 RL-generated demonstrations
(3) Results:
- Dense reward led to successful grasping, but pure RL also succeeded
- Sparse reward resulted in very slow learning
- RL component seemed to dominate learning, questioning the value of demonstrations in this setup
2.3 Residual Policy Learning
To leverage the strengths of both BC and RL, we developed a residual policy approach.
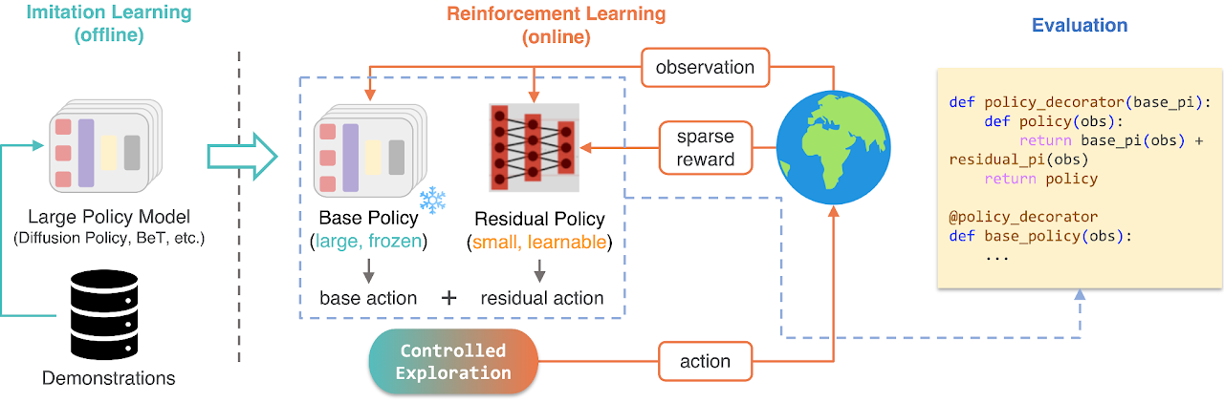
(1) Experimental Setup:
- Base Policy: Fixed BC state-based diffusion policy
- Residual Policy: State-based PPO + BC, trained with sparse reward
- Combined Action: a_total = a_base + w * a_residual
(2) Key Explorations:
- Residual weights (w): {0.004, 0.02, 0.1, 0.3}
- Training epochs: 400 to 2000
- Impact of residual normalization
(3) Results:
- Achieved >95% success rate in simulation
- Significantly faster training compared to PPO+DAPG
- Optimal residual weight found to be task-dependent


2.4 State-to-Visual Policy Transfer (DAgger)
To bridge the gap between state-based and vision-based policies, we employed Dataset Aggregation (DAgger).
(1) Experimental Setup:
- Teacher: State-based policy (trained with residual PPO + BC)
- Student: Visual-based policy (CLIP local features, diffusion model)
- Alternative Student: Point cloud-based policy (PointNet++ encoder)
(2)Key Explorations:
- Iterative data collection and policy improvement
- Comparison of image-based vs. point cloud-based representations
(3) Results:
- Training speed was slower than anticipated
- Highlighted challenges in transferring state-based knowledge to visual domain
2.5 End-to-End Visual Grasping Policies
Finally, we focused on developing end-to-end visual grasping policies, aiming for real-world applicability.
(1) Experimental Setup:
- Input: RGB images (third-person view)
- Model: Transformer-based diffusion policy
- Visual Encoder: CLIP (local features)
(2) Key Explorations:
- Positional encodings: learned embeddings vs. sinusoidal
- Hyperparameter tuning: learning rates, weight decay, batch sizes
- Action sampling strategies
(3) Results:
- Achieved promising results in both simulation and real-world settings
- Local CLIP features outperformed global features
- Careful tuning of hyperparameters proved crucial for success
3. Discussion
Our systematic exploration revealed several key insights:
- Pure imitation learning, while simple to implement, struggles with generalization to new scenarios.
- Combining RL with demonstrations can be powerful, but careful balancing is required.
- Residual policy learning offers a promising direction, leveraging the strengths of both imitation and reinforcement learning.
- Bridging the gap between state-based and vision-based policies remains challenging, highlighting the need for better transfer learning techniques.
- End-to-end visual policies show promise for real-world applications, but require careful architecture design and hyperparameter tuning.
4. Future Work
Based on our findings, several promising directions for future research emerge:
- Exploring more sophisticated visual representations, potentially leveraging large language-vision models.
- Investigating multi-task and meta-learning approaches to improve generalization.
- Developing more efficient exploration strategies for sparse reward settings.
- Integrating tactile feedback to improve grasping precision and robustness.
5. Conclusion
This study provides a comprehensive overview of various learning approaches for robot grasping, from imitation to reinforcement and beyond. By systematically exploring different techniques, we've identified promising directions and key challenges in developing robust, generalizable grasping policies. Our findings contribute to the ongoing effort to bridge the gap between simulated and real-world robotic manipulation.
Bridging Gaps in Robot Manipulation: Reflections on Our Journey
As I sit here, surrounded by robots and lines of code, I can't help but reflect on our recent adventures in the world of robot manipulation. Our journey has been nothing short of fascinating, filled with moments of frustration, surprise, and pure joy. But more than anything, it's been a journey of bridging gaps – three crucial transitions that I believe will shape the future of robotics.
1. From Simulation to Reality: The Unforgiving Leap
Our experiments began in the comfort of simulation. Clean, predictable, and forgiving. We started with behavior cloning, teaching our robots to mimic human demonstrations. It was like teaching a child to draw by guiding their hand – effective, but limited.
As we moved to reinforcement learning techniques like PPO+DAPG, our simulated robots became more adept, learning to grasp objects with increasing precision. But then came the moment of truth – the leap to the real world.
The transition was humbling. Shadows played tricks on our vision systems. Imperfect motors didn't move exactly as commanded. The real world, in all its messy glory, exposed the limitations of our simulated training.
This gap between simulation and reality is more than just a technical challenge. It's a reminder of the complexity of the world we're trying to navigate. As we push forward, I'm excited about the potential of domain randomization and sim-to-real transfer techniques. Perhaps the key lies not in perfect simulation, but in embracing and learning from the imperfections?
2. From State to Vision: Seeing the World Anew
Another significant transition in our research was moving from state-based inputs to visual perception. Initially, our robots knew the exact position of every joint, every object. It was like playing chess with perfect information.
The shift to visual inputs – first RGB, then RGB-D – was like asking our robots to play chess by looking at the board, just as humans do. Our experiments with various visual encoders, from ResNet to CLIP, felt like giving our robots new eyes, each with its own way of seeing the world.
This transition forces us to grapple with fundamental questions about perception and action. How do we distill the complexity of visual information into meaningful actions? Our work with end-to-end visual policies is just the beginning. I'm particularly excited about the potential of large visual-language models in this space. Could we one day have robots that not only see but truly understand their environment?
3. From Imitation to Reinforcement: Learning to Explore
Perhaps the most profound transition was from pure imitation learning to reinforcement learning, and eventually to hybrid approaches like our residual policy method.
We started with behavior cloning – safe, predictable, but limited by the quality of demonstrations. Moving to reinforcement learning was like watching our robots grow up, learning to explore and make mistakes. The sparse reward experiments were particularly telling – like watching a toddler learn to walk, with moments of frustration but also breakthroughs.
Our residual policy approach, combining a fixed behavior-cloned policy with a learned RL component, feels like a metaphor for human learning. We start by imitating, then gradually learn to improvise and adapt.
This journey from imitation to reinforcement learning reflects a deeper question in AI and robotics: How do we balance the knowledge we can impart with the need for autonomous learning? As we push towards more general-purpose robots, this balance will be crucial.
Looking Ahead: The Gaps Yet to Bridge
As I ponder these transitions – sim-to-real, state-to-visual, imitation-to-reinforcement – I'm struck by how they mirror broader challenges in AI and robotics. Each represents a form of generalization, a step towards more adaptable, robust systems.
Looking ahead, I'm excited about several possibilities:
- Multimodal Learning: Combining vision, touch, and even sound for more robust grasping.
- Continual Learning: Developing robots that don't just learn a task but continue to improve over time.
- Semantic Understanding: Moving beyond pure perception to true comprehension of objects and their uses.
Our journey in robot manipulation has been more than a series of experiments. It's been a window into the fundamental challenges of creating machines that can interact with our world as fluently as we do. As we continue to bridge these gaps, I'm reminded that each challenge overcome brings us one step closer to robots that can truly assist and augment human capabilities in meaningful ways.
The gaps we're bridging in robot manipulation are, in many ways, the gaps between artificial and human intelligence. It's a journey that's far from over, but one that promises to revolutionize not just robotics, but our understanding of intelligence itself.